프롤로그: 기술적 분석에서 AI 유사 패턴으로
기술적 분석은 본래 시장 참여자가 반복해서 만드는 패턴에서 출발했다. 가격·거래량·캔들 조합과 몇 가지 지표를 통해 “이런 모양이 나오면 대체로 이렇게 흘렀다”를 경험과 통계로 축적한 셈이다. 과거에는 데이터와 연산 역량이 제한되어, 사람이 눈으로 차트를 고르고 지표를 보며 해석하는 과정이 전부였다.
지금은 다르다. 인공지능과 대규모 연산 덕분에, 굳이 지표를 만들고 해석하는 중간 단계 없이도 수많은 차트를 직접 비교해 유사 패턴을 찾을 수 있다. 더 나아가 그 패턴들이 이후에 어떻게 전개되었는지의 분포를 즉시 꺼내볼 수 있다. 요컨대 패턴의 통계로부터 미래의 통계를 조심스럽게 가늠하는 접근이다.
이 프로젝트는 그 생각에서 시작했다. “유사한 패턴을 가진 과거 차트들의 성과 분포를 현재 위에 겹쳐 보여주면, 예측을 단일 수치가 아닌 가능성의 범위로 볼 수 있지 않을까?” 이 방식은 퀀트 투자의 문법과도 잘 맞는다. 정답을 찍기보다, 분포로 리스크를 읽고 의사결정을 보조하는 도구—그래서 유사 패턴 스캐너와 분포 기반 의사결정을 핵심으로 하는 보조도구를 직접 만들었다.
내가 만들고자 하는 것, 한 문장 요약
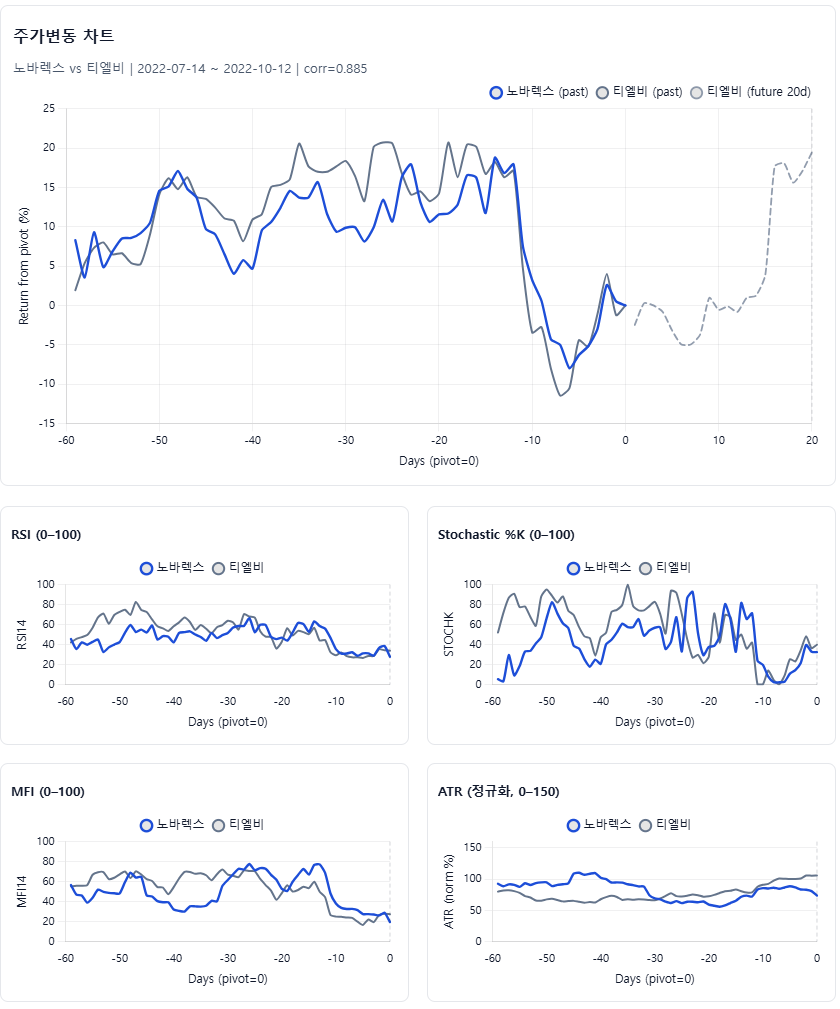
결론부터 말하면, 타깃 종목의 최근 60거래일 차트 데이터를 만들고, 코스피·코스닥 전 종목의 지난 10년 데이터를 통틀어 유사 구간을 찾아 현재 차트 위에 겹친 다음, 그때 이후 +20일 성과의 분포를 보여주는 보조도구다. 정답을 찍기보다 가능한 범위와 미래의 주가 상승확률 분포를 보여주는 데 무게를 뒀다.
데이터와 기본기: 일단 가볍고 단단하게
처음부터 거창하게 가지 않았다. pykrx로 KRX 일봉(시가·고가·저가·종가·거래량)을 받아 Parquet로 차곡차곡 쌓고, 유사성 평가는 가격만 보지 않았다. 단순 종가 비교를 넘어서, 기술적 분석에서 의미가 큰 RSI, StochK, MFI, ATR 네 가지 보조지표를 함께 포함해 차트+지표의 결합 벡터로 스캔했다. 일봉도 종가만 쓰지 않고 시가·고가·저가를 모두 반영해 캔들의 맥락을 놓치지 않도록 했다.
데이터 갱신은 날짜 커트라인을 두고 증분만 가져온다. 저장은 항상 임시 파일에 먼저 기록 → 검증 후 원자적(rename) 교체 순서로 처리했다. 한 번 신뢰가 흔들린 데이터는 끝까지 발목을 잡는다—그래서 입출력은 빠르고 안전하게, 규칙은 단순하고 반복 가능하게 맞췄다.
임베딩과 검색: “비슷하다”를 수치로 만들기
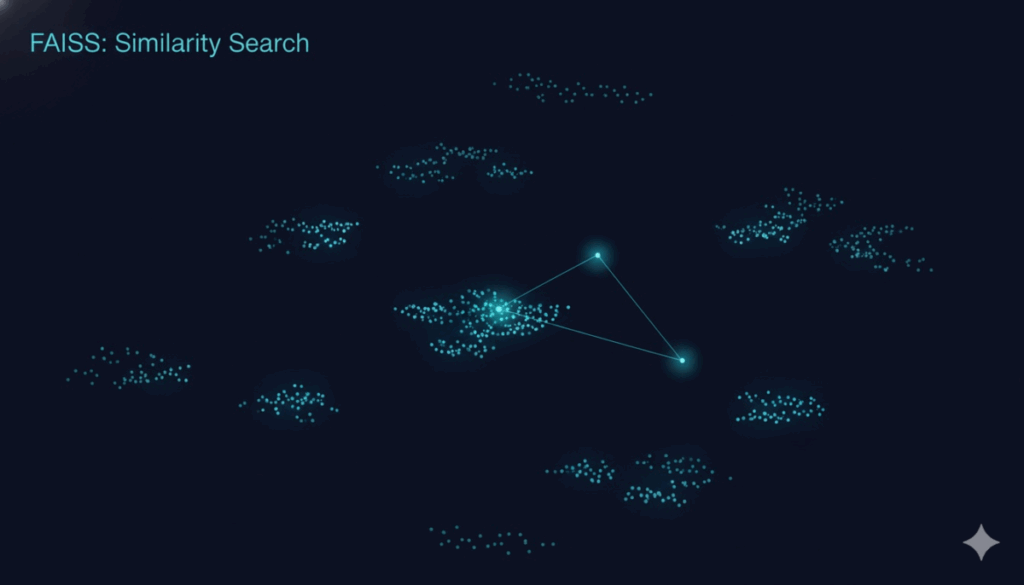
사람 눈으로 느끼는 “이 구간, 어디서 본 것 같아”를 그대로 흉내 내고 싶었다. 그래서 최근 60거래일을 하나의 덩어리로 잘라 수익률 기준으로 크기를 맞춘 뒤 숫자 목록(벡터)로 만들었다. 그다음 이 벡터를 과거 전 기간과 빠르게 대조해 가장 비슷한 3개만 뽑아온다. 여기서 핵심은 속도인데, 수년치 차트를 전부 맞대면 비교 횟수가 기하급수로 늘어난다. 그래서 “비슷한 것을 번개처럼 찾아주는 검색기”(= FAISS)를 붙였다.
또 최근 구간과 거의 겹치는 케이스가 뽑히지 않도록 최소 10거래일 이상 떨어진 구간만 후보로 받는다. 이 정도만 해도 사람이 차트를 일일이 뒤질 필요가 크게 줄고, “과거의 비슷한 상황”을 금방 확인할 수 있다.
왜 ‘검색기’가 필요했나, 그리고 FAISS란?
유사 구간을 찾겠다고 수년치 KRX 차트 전부를 60일씩 잘라 전부 서로 비교하기 시작하면, 비교 횟수가 수억 번까지 불어난다. 사람도, 보통 컴퓨터도 정면승부로는 버티기 어렵다.
그래서 쓴 게 FAISS(Facebook AI Similarity Search) — 메타(구 페이스북)가 공개한 “비슷한 것끼리를 미친 듯이 빨리 찾아주는” 라이브러리다.
아이디어는 단순하다.
- 동네 서점처럼 비슷한 책은 같은 코너에 꽂아두면, 나중에 찾을 때 그 코너만 뒤지면 된다.
- 차트도 마찬가지다. 60거래일을 숫자 목록(벡터)로 바꾼 뒤, 비슷한 벡터들끼리 먼저 묶어 두고, 안 비슷한 덩어리는 아예 안 본다.
- 그러면 “지금 차트와 비슷한 상위 3개”를 순식간에 뽑아낼 수 있다.
내 도구의 흐름은 이렇다:
60일 차트 → 수익률 기준으로 크기 맞춤 → 숫자 벡터화 → FAISS에 넣기 → 지금 구간과 비슷한 과거 3개 바로 찾기.
정확히 전부를 일일이 대조하는 대신, 거의 같은 결과를 훨씬 빠르게 얻는 방식이다(실무에선 이 속도가 핵심이다).
API: 필요한 것만, 얇고 확실하게
백엔드는 FastAPI로 역할만 딱 나눈 4개의 엔드포인트로 아주 얇게 뼈대만 잡았다.
- 엔드포인트 A(티커 해상도)
자연어 입력(예: “삼성전자”)을 거래소 코드로 바꿔준다.
입력: 종목명/심볼 문자열 → 출력: 표준화된 티커/시장 정보 - 엔드포인트 B(데이터 보유 확인)
“이 티커·이 윈도우의 데이터가 준비돼 있나?”를 빠르게 체크한다.
입력: 티커, 윈도우 길이 → 출력: 존재 여부(bool), 최신 날짜 등 메타 - 엔드포인트 C(유사 패턴 요약)
최근 60거래일과 비슷한 과거 Top-K를 찾아주고, 각 사례의 +5/+10/+20일 성과 요약을 돌려준다.
입력: 티커, 윈도우, Top-K, FWD 일수 → 출력: 유사 구간 목록, 수익률 요약(중앙값·IQR 등) - 엔드포인트 D(오버레이 시계열)
사용자가 고른 특정 매치의 과거·현재·미래 구간 시계열을 보내서 차트에 그대로 겹쳐 그릴 수 있게 한다.
입력: 티커, 선택한 매치의 식별값 → 출력: 시계열(OHLC/지표), 정렬용 타임스탬프
운영 쪽은 최대한 단순하게 했다. 연산이 길어질 때는 결과를{ticker}|{W}|{TopK}|{FWD} 같은 짧은 키로 캐시하고, 응답은 필요한 필드만 남긴다. 인증·레이트리밋은 헤더 기반으로 붙일 계획이고, 내부 파라미터 검증 규칙이나 상세 로직은 굳이 외부에 드러내지 않았다. 현장에서 믿을 건 단순한 인터페이스 + 얇은 응답이었다.
배포·운영 경험담: “구글 서버 갈까?” 하다 결국 로컬로
처음엔 “깔끔하게 클라우드(구글 서버) 에 올릴까?”를 생각했다. 자동 확장, 고정 도메인, 모니터링… 머릿속 그림은 완벽했다.
현실은 달랐다. 빌드·권한·네트워킹이 한 번에 맞아떨어지지 않았고, 코드 한 줄 바꿀 때마다 컨테이너 재빌드/재배포를 반복했다. 예상 밖의 지연도 있었고, 디버깅 루프가 길어지니 흐름이 자꾸 끊겼다. 무엇보다, 내가 자주 하는 시행착오성 실험엔 손이 바로 닿는 로컬 서버가 훨씬 빨랐다.
그래서 초반 운영은 로컬 PC를 예측 서버로 쓰는 쪽을 택했다. 파이썬 가상환경에 uvicorn만 있으면 바로 띄우고, 로그를 눈앞에서 보면서 수정→재시작까지 분 단위로 돌릴 수 있다. 파일 I/O나 캐시 병목도 금방 감이 온다.
물론 단점도 확실했다. 외부 접근을 위해 Cloudflare Tunnel을 썼는데, 프로그램을 재시작할 때마다 URL이 새로 생기는 게 너무 불편했다. 무료로 간단히 열어두는 대신, 매번 새 주소를 받아서 붙여야 한다는 점이 특히 귀찮았다.
결론적으로, 초기 개발/실험은 로컬 + 터널 조합이 가장 빠르고, 서비스 전환을 생각할 땐 고정 도메인(리버스 프록시나 유료 터널, 혹은 클라우드)로 옮기는 게 맞다. 덧붙이면, 서버용 소프트웨어를 처음 만들어보는 입장이라 배우면서 진행하느라 정말 힘들었다. 권한/네트워크/배포 도구가 한 번에 머리에 들어오지 않아서, “왜 안 뜨지?”를 하루에도 몇 번씩 되뇌었다. 그래도 한 고비 넘길 때마다 다음 수정이 빨라지는 걸 체감했고, 지금 이 글도 그런 시행착오의 기록이다.
동작 후기 & 다음 할 일
직접 돌려보니 “이 정도로 비슷해?” 싶은 케이스가 꽤 나왔다. 반대로, 눈으로 봐도 크게 비슷하지 않아 보이는 결과도 섞여 있었다. 곰곰이 생각해보니, 내가 종가만 본 게 아니라 시가·고가·저가까지 포함하고, 거기에 RSI·StochK·MFI·ATR 같은 보조지표까지 함께 비교했기 때문일 것이다. 즉, 겉모양(캔들 패턴)만 닮은 게 아니라 내부 리듬(변동성·모멘텀) 까지 보려다 보니, 사람이 첫눈에 느끼는 유사성과 수치로 본 유사성 사이에 간혹 간극이 생긴다. 이건 단점이자 장점이다. 사람 눈이 놓치는 부분을 모델이 끌어올 수 있고, 반대로 모델이 과하게 민감한 지점을 사람이 거르고 교정할 수 있다.
앞으로는 이 간극을 줄이기 위해 결과 해석 레이어를 더 얹을 생각이다. 특히:
- 분포 시각화 추가: 선택한 종목의 유사 사례에 대해 +10일 / +20일 수익률 분포를 박스플롯(또는 바이올린 플롯)으로 바로 보여준다. 중앙값, IQR, 극단값을 한눈에 보게 해서 “가능한 범위”를 직관적으로 전달.
- 유사도 가중 보기: 단순 Top-K 나열이 아니라, 유사도 점수를 가볍게 가중해 가중 중앙값/가중 분위도 함께 표기.
- 필터 옵션: 사용자가 결과를 보며 즉석에서 업종/시가총액/변동성 구간으로 재필터링할 수 있게 최소한의 토글 제공.
- 설명 툴팁: “왜 이 사례가 골라졌나?”를 간단히 풀어주는 미니 설명(예: 변동성/RSI 패턴 근접) 추가.
요약하면, 지금 버전은 비슷한 과거를 빠르게 보여주는 스캐너” 로 쓸만한 수준까지 왔다. 다음 단계는 그 결과를 “어떻게 해석할지”를 더 잘 보여주는 쪽—특히 +10·+20일 분포 시각화를 최우선으로 붙여, 판단의 과신을 낮추면서도 결정을 더 빨리 내릴 수 있게 만드는 것이다.
주가 유사 패턴 스캐너 사용해 보기
 통계적 기반의 주가 예측
AI가 골라낸 유사패턴으로 미래의 가능성을 미리 비교하세요. 가격·보조지표를 같은 축에서 겹쳐 보며 유사 구간의 이후 20일 흐름을 참고합니다.
통계적 기반의 주가 예측
AI가 골라낸 유사패턴으로 미래의 가능성을 미리 비교하세요. 가격·보조지표를 같은 축에서 겹쳐 보며 유사 구간의 이후 20일 흐름을 참고합니다.